
Most personal brand websites are glorified business cards. They have a headshot, a bio, maybe a contact form, and they do absolutely nothing for discoverability. Meanwhile, the actual proof of authority, the videos, podcasts, stories, and speaking events, lives scattered across YouTube, Apple Podcasts, LinkedIn, and Google Business Profile with no structured connection between any of it.
This is a Claude skill file that contains a complete engineering specification for building a personal brand website on WordPress that actually works for Google.
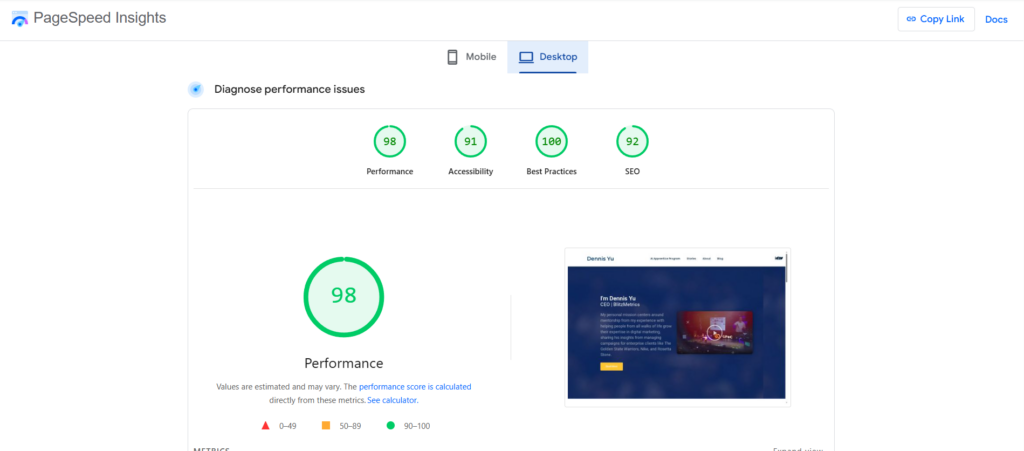
It is built around our platform and takes an entity-first approach: everything ties back to a Person or Organization, every piece of content maps to topics and offers, and every page ships with validated JSON-LD schema.
Drop it into a Claude Project and it becomes your technical co-pilot for the entire stack. The spec covers system architecture, the WordPress data model with custom post types and taxonomies, ingestion connectors for six platforms, transcription and enrichment pipelines, video-to-article repurposing, JSON-LD schema generation, internal linking logic, performance targets, analytics instrumentation, editorial workflows, API design, security, and a prioritized backlog. It is not a theme. It is the engineering blueprint underneath one.
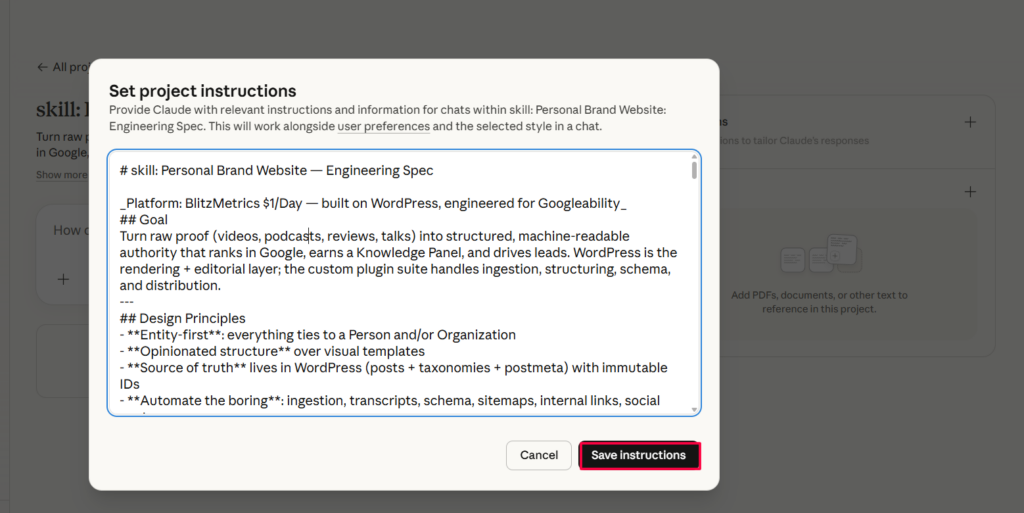
To use it, create a new Claude Project at claude.ai, add the Markdown below as a skill file under Project Knowledge, and start asking Claude to help you build, audit, or extend your personal brand site.
The skill file
Copy everything below and add it to your Claude project as a skill file.
skill: Personal Brand Website: Engineering Spec
Goal
Turn raw proof (videos, podcasts, reviews, talks) into structured, machine-readable authority that ranks in Google, earns a Knowledge Panel, and drives leads. WordPress is the rendering and editorial layer; the custom plugin suite handles ingestion, structuring, schema, and distribution.
Design principles
Entity-first: everything ties to a Person and/or Organization. Opinionated structure over visual templates. Source of truth lives in WordPress (posts + taxonomies + postmeta) with immutable IDs. Automate the boring: ingestion, transcripts, schema, sitemaps, internal links, social posts. Measure or it didn’t happen: GA4, GSC, GBP, YouTube Analytics feed into a unified KPI layer. SEO-safe by default: canonical rules enforced, noindex traps guarded, schema linted.
1. System architecture
Core stack
Managed WordPress (PHP 8.2+, MariaDB/Aurora MySQL), NGINX/HTTP3, PHP-FPM. Custom plugin monorepo: blitz-pb-engine with modules:
ingest/ handles connectors for YouTube, Apple/Spotify, Instagram, LinkedIn, GBP, and Google Sheets. transcribe/ provides a Whisper or Amazon Transcribe adapter. repurpose/ runs the video-to-article pipeline and snippet generator. schema/ builds and validates JSON-LD. linker/ manages the internal linking graph. sitemaps/ generates video, news, and standard sitemaps. kpis/ pulls data from GA4, GSC, GBP, and YouTube into dashboards. api/ exposes a REST API and WP-CLI interface. jobs/ handles queues and retries.
Infrastructure
Storage uses AWS S3 for media and transcripts, CloudFront CDN for delivery, and imgproxy for image transforms. Queue and cron runs on WP-Cron plus server cron, with optional SQS for bursty ingestion. Cache layers include FastCGI plus Redis object cache and page CDN cache via CloudFront or Cloudflare. Logs and observability run through CloudWatch plus WP debug logs, with optional OpenTelemetry. An optional headless setup uses WPGraphQL feeding a Next.js or Remix front-end, though the default is a server-rendered theme.
2. WordPress data model
Custom post types (CPTs)
| CPT | Description |
|---|---|
person | The human brand entity (1 primary required) |
organization | Company/brand entity |
asset_video | YouTube/native video |
asset_podcast | Apple/Spotify episode |
asset_article | Long-form post auto-generated from video/podcast |
testimonial | Review/UGC (text or video) |
offer | Productized service, package, price anchor |
topic_hub | Topic Wheel nodes (5 to 7 recommended) |
event_speaking | Talks, panels, media appearances |
Taxonomies
| Taxonomy | Description |
|---|---|
topic (hierarchical) | Matches topic_hub pages (term ≈ entity topic) |
persona | ICP tags (e.g., “Wisconsin homeowner”, “Roofing GM”) |
geo | City/region/state (used for GBP + local SEO) |
platform | Source systems (YouTube, IG, LinkedIn, Apple, Spotify) |
Key postmeta fields
entity.person_id and entity.org_id serve as foreign keys. source.url, source.platform_id, and source.published_at track origin. transcript.s3_uri and transcript.word_count reference transcript storage. repurpose.status tracks the pipeline state: queued | draft | needs_review | published. schema.type maps to VideoObject, PodcastEpisode, Review, FAQ, or Event. kpi.impressions, kpi.ctr, and kpi.entity_coverage store performance data.
Relationship rules
Asset connects to Topic via the topic taxonomy with a relevance score from 0 to 1. Asset connects to Offer via postmeta offer_ids (array). Testimonial requires an Offer link; Persona is optional. Person connects to Organization via primary_org_id. The rule: no orphan assets. Every asset_* must map to at least one topic or offer.
3. Ingestion connectors
YouTube
Method: YouTube Data API v3 by Channel ID; webhook via PubSubHubbub if enabled. Fields: videoId, title, description, tags, publishedAt, thumbnails, duration. Creates asset_video; thumbs fetched to S3; thumb.s3_uri stored.
Podcasts (Apple/Spotify)
Method: RSS polling plus Spotify API enrichment. Fields: guid, title, summary, audio URL, pubDate, duration. Creates asset_podcast; audio enclosures optionally proxied to S3.
Instagram / LinkedIn
Method: Graph API (user auth) for media and captions; LinkedIn shares via REST. Creates asset_video (if video) or asset_article (short form). Canonical remains the source network; rel=canonical applied if mirrored.
GBP (Google Business Profile)
Method: GBP API for reviews and posts. Reviews become testimonial (rating, reviewer initials); GBP posts become asset_article with geo tags.
Google Sheets bulk upload
Method: Sheet columns [Title, URL, Type, Topic, Offer, Date, Notes]. Creates CPTs; idempotent by URL hash.
Validation and idempotency
Source URL hash unique index prevents duplicates. Retries use exponential backoff; poison queue handles persistent failures.
4. Transcription and enrichment pipeline
Step 1, Transcribe: Whisper (local) or Amazon Transcribe (batch) produces SRT/VTT plus JSON. Step 2, Chunking: semantic chunking at 500 to 1000 tokens with timestamps. Step 3, Summaries: TL;DR, key quotes, entities (People, Orgs, Places, Products) written to postmeta. Step 4, Highlights extraction: candidate H2s; FAQ pairs (Q/A) scored. Step 5, Compliance: optional profanity filter and PII redaction. Step 6, Storage: transcripts in S3 at transcripts/{postID}.json; short excerpt in postmeta.
5. Repurposing: video to article generator
State machine (repurpose.status)
queued means a new asset is eligible. draft means an AI draft has been created. needs_review means an editor pass is required. published means it has been converted to asset_article and indexed.
Article blueprint
H1 comes from the value proposition; byline is the Person. Intro is benefit-led, body sections are built from highlights. Pull-quotes and callouts are auto-placed every 300 to 400 words. FAQ (2 to 5 Q/A) is included only if confidence meets the threshold. CTAs include the primary offer plus city and persona variants.
Internal links insertion
First mention of each Topic links to topic_hub. If an Offer is mentioned, it links to the offer page. If a testimonial exists for that Offer, a sidebar card is injected.
6. Schema (JSON-LD) generation
Global (on home/about)
Person, Organization, WebSite plus SearchAction.
Per content type
| CPT | Schema type |
|---|---|
asset_video | VideoObject (+ UploadDate, Duration, ThumbnailUrl, Transcript, about, mentions) |
asset_podcast | PodcastEpisode with isPartOf PodcastSeries |
asset_article | Article / BlogPosting with Author (Person), about, mentions |
testimonial | Review with itemReviewed (Offer/Organization), reviewRating |
event_speaking | Event (location, startDate, organizer) |
offer | Service / Product (price, areaServed, offers) |
Validation: build and lint server-side; block publish if fatal schema errors.
7. Internal linking and navigation rules
Topic hubs list the top 5 assets by topic_score * recency. Contextual links target the first occurrence per section, with a max of 1 link per 150 words to avoid spam. Breadcrumbs follow the pattern Entity → Topic → Asset. Canonicalization: if the source is external (YouTube/LinkedIn), the article is canonical unless 80% text overlap exists, in which case rel=canonical points to the source. Sitemaps are segmented into /sitemap-assets.xml, /sitemap-topic-hubs.xml, and /video-sitemap.xml.
Asset scoring formula
score = (0.6 * topic_relevance) + (0.3 * freshness_decay) + (0.1 * engagement)8. Performance and Core Web Vitals (CWV)
SSR theme with minimal JS; defer non-critical scripts. Critical CSS inlined per template; font-display: swap. Lazy-load images and video; responsive srcsets. Redis object cache; full-page cache via CDN. Targets: LCP < 2.0s, INP < 200ms, CLS < 0.05 on 4G mid-tier.
9. Analytics and KPIs
Data sources
GA4 (events), GSC (queries/CTR), GBP (impressions/calls), YouTube (views/watch time), server logs.
Collected KPIs
Branded search impressions (GSC). Branded CTR (GSC). Entity coverage percentage (assets with Topics, Offers, schema OK). Review velocity (GBP, per month). Lead events (GA4: generate_lead, submit_form, tel: clicks).
Storage and surfacing
Pull nightly via cron into WP kpis module tables; cache last 30/90 days. Admin dashboard cards plus sparkline.
10. Editorial workflow
Roles: Creator, Editor, Publisher, Engineer. Ingestion auto-creates asset_* in queued. Editors see the queue with confidence scores and suggested titles.
WP-CLI commands:
wp blitz ingest youtube --channel=UCxxxxx
wp blitz transcribe run --post=123
wp blitz repurpose build --post=123
wp blitz publish --post=12311. REST API endpoints
Base: /wp-json/blitz/v1
| Endpoint | Description |
|---|---|
POST /ingest | Body: {url, type} enqueue a single asset |
POST /repurpose/{post_id} | Build article draft |
POST /publish/{post_id} | Publish with validations |
GET /kpis | Range filters, aggregates |
GET /entities | List Persons/Orgs with linkage |
Auth: Application Passwords or JWT; rate-limit per IP/token.
12. Security, privacy, and compliance
Principle of least privilege for API tokens (YT/GBP/Meta/LinkedIn). Secrets managed via environment vars plus AWS Secrets Manager. Reviewer initials only for GBP reviews (no doxxing); allow redaction. Backups: DB (hourly PITR), uploads/S3 (versioned), configs in Git. OAuth permissions may expire so token refresh plus alerts are implemented. Podcast RSS inconsistencies (GUID reuse) use URL hash fallback. If creators delete source videos, preserve canonical and 410 accordingly.
16. Backlog / next up (prioritized)
- GBP Post Scheduler from inside WP with UTM tagging
- Auto-FAQ generator with confidence thresholds plus human-in-the-loop
- Entity Graph UI: visualize Person/Org/Topic/Asset relationships
- OpenSearch integration for on-site semantic search
- Tuned Whisper with diarization plus speaker labels
- Partner Mentions Miner: discover likely podcasts/press to pitch
- Programmatic Local Pages: geo x offer grid with canonical rules
- Video Chapters to How-To/Clip pages with structured data
- GSC anomalies detector (alerts on CTR/impressions drops)
- Multi-tenant hardening for agency roll-outs (namespaces, caps)
TL;DR for engineers
WordPress is the CMS and permissioned UI, but the core win is the structured entity/topic model, automated ingestion-to-repurpose pipelines, and first-class schema plus internal linking tuned for Google’s entity understanding. This is not a theme. It is an opinionated content OS for personal brands.